1-1-1. 인덱스
클러스터형 인덱스 - PK랑 비슷, 한개만 가능
비클러스터형 인덱스 - 여러개 생성가능, 조건절에서 비클러스터형 인덱스 걸기 가능
인덱스를 거는 필드가 NULL값이 많이 들어있으면 성능이 떨어진다.
*설정한 인덱스 확인하는 방법

*클러스터형 인덱스의 특징
1. 생성시 데이터페이지 전체를 다시 정렬한다. 그렇기 때문에 시스템 부하를 줄 수 있다.
2. 인덱스 자체의 리프 페이지가 곧 데이터이다. 클러스터형 인덱스는 테이블에 1개만 생성가능하다.
3. 비클러스터형 인덱스보다 검색속도는 빠르다. 하지만, 데이터의 입력/수정/삭제는 더 느리다.
*비클러스터형 인덱스의 특징
1. 생성시 데이터페이지는 그냥 둔 상태에서 별도의 인덱스를 구성한다.
2. 클러슽어형보다 검색속도는 더 느리지만, 데이터의 변경은 더 빠르다.
3. 비클러스터형 인덱스는 여러 개 생성할 수 있다. 하지만, 함부로 남용시 시스템의 혼잡을 야기시킬 수 있다.
*인덱스의 사용
데이터의 중복이 많으면 인덱스를 만들어도 별 효용이 없다.
where 절에서 사용되는 컬럼을 인덱스로 만들어라.
where 절에 사용되더라도 자주 사용해서 가치가 있다.
2-1-1. 트랜젝션
하나의 논리적 작업단위로 수행되는 일련의 작업
SQL문 (SELECT/INSERT/UPDATE/DELETE)의 묶음
한 단위의 트랜잭션은 모두 처리되거나, 모두 처리 되지 않도록 DNMS가 관리해 준다.
형식 :
BEGIN TRANSACTION (BEGIN TRAN)
SQL 문장들
COMMIT TRANSACTION (COMMIT TRAN, COMMIT WORK)
*UPDATE문
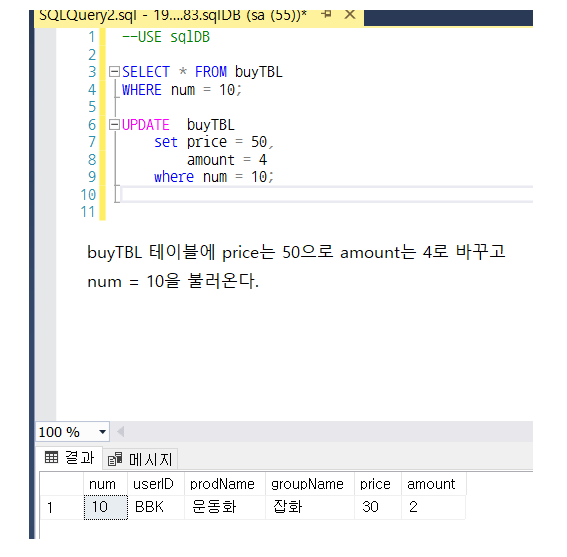
2-1-2. 트랜젝션 사용 - REVIEW하기
COMMIT이랑 ROLLBACK을 할려면 BIGIN TRAN을 실행하고 해야함.

*트랜잭션의 특징
1. 원자성 : 분리할 수 없는 하나의 단위로써, 작업이 모두 수행되거나 하나도 수행되지 않아야 한다.
2. 일관성 : 사용되는 모든 데이터는 일관되어야 한다.
3. 격리성 : 현재 트랜잭션이 접근하고 있는 데이터는 다른 트랜잭션에서 격리되어야 한다.
4. 영속성 : 트랜잭션이 정상적으로 종료된다면 시스템 오류가 발생하더라고 그 결과는 시스템에 영구적으로 적용된다.
3-1-1. 데이터베이스 모델링
: 현 세계에서 사용되는 작업(행위)이나 사물을 데이터베이스 개체로 옮기는 과정
4-1-1. 저장 프로시저 ( C# 메서드랑 비슷한 개념)
: 쿼리문의 집합, 어떤 동작을 일괄 처리할 때 사용된다.
저장 프로시저도 데이터베이스의 개체 중 하나이기 때문에 테이블처럼 각 데이텁제이스 내부에 저장된다.
4-1-2. 저장 프로시저 만들기

4-1-3. 저장 프로시저 불러오기

4-1-4. 파라매터 설정

4-1-5. OUTPUT 하기 (RETURN)

4-1-6. IF절

4-1-7. CASE문


4-1-8. 저장 프로시저의 특징
ㄱ . SQL SERVER의 성능을 향상시킬 수 있다. (속도가 빠르다)
ㄴ . 유지관리가 간편하다.
ㄷ . 모듈식 프로그래밍이 가능하다.
ㄹ . 보안을 강화할 수 있다.
ㅁ . 네트워크 전송량의 감소
5-1-1. 사용자 정의 함수 (스칼라 반환 함수) : 스칼라 값 하나만 반환

5-1-2. 사용자 정의 함수 (테이블 반환 함수)
: 테이블 자체를 반환해준다.


'MS-SQL' 카테고리의 다른 글
| 2020.06.12(금) - DB (0) | 2020.06.12 |
|---|---|
| 2020.06.10(수) - DB (0) | 2020.06.10 |
| 2020.06.09(화) - DB (0) | 2020.06.09 |
| 2020.06.08(월) - DB (0) | 2020.06.08 |
| 2020.06.05(금) - DB (0) | 2020.06.05 |